Guía de IA Directiva
Cómo la IA cambió de fase y por qué Q1 2026 es tu momento
Índice
Historia de la IA
70 años de evolución
Cómo funciona la IA
Conceptos fundamentales
Tipos de modelos
Familias y aplicaciones
Ecosistema IA
Herramientas y plataformas
Prompting profesional
Técnicas y mejores prácticas
Q1 2026: Tu momento
Plan de acción
Historia de la IA
Panorama general: la IA cambió de fase
70 años de historia
Hecho histórico: la Inteligencia Artificial (IA) es un campo con más de 70 años de historia.
Durante décadas ha alternado periodos de optimismo ("ya casi lo logramos") con etapas de decepción y recortes ("AI winters").
Lo importante para una empresa hoy
No es memorizar fechas, sino entender qué cambió en 2022–hoy para que la IA pasara de ser una tecnología reservada a especialistas a convertirse en una herramienta usable por directivos y equipos no técnicos.
El gran cambio: Accesibilidad
La gran transición reciente no es únicamente un incremento de "inteligencia", sino un cambio de accesibilidad: por primera vez, muchas capacidades avanzadas se empaquetan en interfaces simples (chat, copilots integrados, herramientas SaaS) y se pueden conectar con procesos reales sin montar un departamento de datos desde cero.
La primera era: IA Simbólica (1950s–1980s)
Idea central: "inteligencia por reglas"
Los inicios de la IA se asociaron a la idea de que el pensamiento humano podía formalizarse como lógica y reglas. Si se definían suficientes "si ocurre A, entonces hacer B", una máquina podría comportarse de manera inteligente.
Ventajas
- Muy eficaz en dominios cerrados y estructurados
- Transparente: se rastrea qué regla se aplicó
Limitaciones
- Fragilidad: el mundo real es demasiado variado
- Escalabilidad baja: mantenimiento exponencial
- Dependencia de expertos: caro y lento
Resultado
Sistemas expertos de los 80, útiles pero con adopción masiva limitada por su rigidez y mantenimiento.
El gran cambio: Machine Learning (1990s–2010s)
Nuevo paradigma
Con Machine Learning (ML) el enfoque se invierte: en lugar de programar reglas, se alimenta al sistema con datos y ejemplos para que aprenda patrones.
Impacto en negocio
Automatizó decisiones repetitivas y habilitó modelos predictivos en operaciones clave.
- Automatización de decisiones repetitivas
- Predicción: impago, demanda, churn
- Optimización: rutas, inventarios, pricing
Barreras reales
- Datos estructurados y consistentes
- Equipos técnicos especializados
- Ciclos largos de desarrollo
Por qué no llegó a pymes
El coste de datos, talento y tiempo hacía difícil escalar ML en empresas pequeñas sin infraestructura previa.
Deep Learning (2012–2020)
Qué lo hizo posible
Habilidades desbloqueadas
El cuello de botella
Aún así, entrenar y desplegar seguía siendo complejo: requería expertos, infraestructura cara y meses de trabajo. No llegaba a pymes.
El salto que lo cambió todo: Transformers (2017–hoy)
La revolución arquitectónica
Los Transformers (2017) eliminaron el procesamiento secuencial mediante Self-Attention: cada elemento atiende directamente a otros según relevancia.
RNN/LSTM (antes)
- Procesamiento secuencial
- Contexto limitado
- Poco paralelizable
Self-Attention
- Paralelo completo
- Contexto global
- Escalable
El resultado
- Modelos gigantes (billones de parámetros)
- GPT, Claude, Gemini
- IA conversacional real
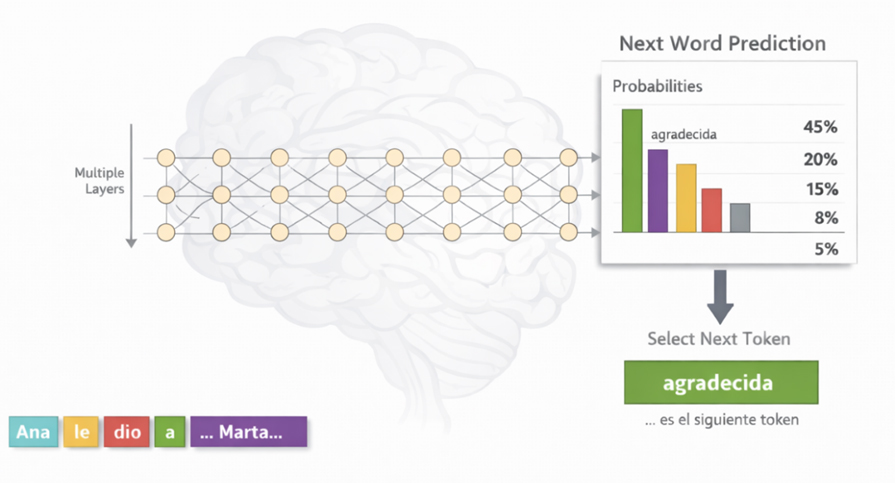
Self-Attention: la clave que lo explica todo
¿Qué hace self-attention?
Cuando el modelo procesa cada palabra (token), no la interpreta sola. Para cada token, calcula a qué otras palabras debe "prestar atención" para entenderla mejor.
"Ana le dio a Marta su libro porque estaba agradecida"
¿Quién estaba agradecida? ¿Ana o Marta?
En particular: el token "agradecida"
El modelo asigna pesos (simplificado) a cada palabra:
Self-Attention: la clave que lo explica todo
Cómo funciona la IA
La idea central: Modelo ≠ Herramienta; Entrenar ≠ Usar
Separar claramente el motor, el producto y los momentos de uso.
Modelo
El "motor" matemático que convierte entrada en salida (texto, clasificación, imagen, audio, decisión).
Herramienta
El producto que envuelve ese motor (interfaz, permisos, integraciones, almacenamiento, controles).
Entrenamiento
El proceso de construir el modelo: aprendizaje a partir de datos.
Inferencia
El momento de uso: metes una entrada y el modelo produce un output.
Muchos riesgos, costes y resultados dependen más de la herramienta (controles, privacidad, integración) y de la inferencia (cómo preguntas) que del modelo en abstracto.
Pipeline conceptual: Datos → Entrenamiento → Modelo → Respuesta
Una forma simple (y rigurosa) de entenderlo:
Pipeline conceptual
1. Datos
Ejemplos del mundo real
2. Entrenamiento
Ajustar parámetros
3. Modelo
Conocimiento estadístico
4. Instrucción + Contexto
Tu prompt + documentos
5. Respuesta
Probabilística, no determinista
La clave
El modelo no "busca" la verdad. Produce texto que es probable dado lo que vio en entrenamiento + el contexto que le das ahora.
Entrenamiento de un LLM: predecir el siguiente token
Entrenamiento
El modelo aprende a predecir el siguiente token en millones de documentos.
Punto importante
Este aprendizaje NO es una base de datos exacta. Es más parecido a un "compresor" de patrones. Por eso puede generalizar, pero también puede inventar cuando no tiene evidencia suficiente.
Instrucción y alineamiento: por qué un LLM "obedece"
Un LLM preentrenado completa texto, pero no necesariamente sigue instrucciones bien. Por eso se añaden capas de instrucción y alineamiento.
La idea base
Un modelo base es bueno completando, pero no entiende prioridades ni formato sin entrenamiento específico.
Problema base
Completa texto, pero falla en intención, formato y prioridades.
Instruction Tuning
Entrenamiento con pares instrucción→respuesta para fijar el patrón de obedecer y devolver formatos.
Se nota en dos fenómenos
Un modelo puede ser “inteligente” pero poco obediente, y dos herramientas similares pueden dar experiencias distintas.
Alineamiento (RLHF/DPO)
Para que sea más útil, más seguro y más consistente con valores humanos.
Contexto: ventana limitada y "memoria" no equivalente
LLMs trabajan con una ventana de contexto
Número máximo de tokens que pueden considerar en una interacción. Todo lo que esté fuera no se "ve" en ese momento.
Implicaciones prácticas
También explica...
Por qué en un chat largo el modelo puede contradecirse: parte del contexto relevante puede quedar fuera o tener menos "saliencia" (relevancia percibida).
"Alucinaciones": por qué ocurren y cómo pensar en ellas
¿Qué es una alucinación?
"Alucinación" = cuando el modelo genera información falsa o no sustentada. No es un "bug raro"; es un resultado natural del funcionamiento.
¿Por qué ocurren?
El modelo optimiza la probabilidad de tokens plausibles. Sin evidencia suficiente, completa huecos con lo que "suena correcto".
Factores de riesgo
Cómo reducirlas
IA Generativa vs IA Predictiva/Clásica
Dos "familias" de casos de uso en la empresa:
IA Predictiva
(ML Tradicional)
Entradas: estructuradas (tablas)
Salidas: numéricas o clases
Ejemplos: prob. impago, demanda, anomalías
Ventaja: más estable y medible
IA Generativa
(LLMs y Multimodal)
Entradas: no estructuradas (texto, docs)
Salidas: textuales/estructuradas generadas
Ejemplos: resumen, tabla, propuesta, SOP
Ventaja: ROI temprano en trabajo
📊 En pymes: cómo comienza la transformación
Fase 1 (Rápida)
IA Generativa
Documentos, comunicación, reporting
Fase 2 (Madurez)
IA Predictiva
Con datos más consolidados
"Grounding" y RAG: haciendo que la IA responda con tu realidad
IDEA CLAVE
Obliga al modelo a responder basándose solo en tus datos. Sin grounding, la IA inventa.
Grounding
"Responde solo con lo que te doy" — Obliga al modelo a basar la respuesta en un conjunto de evidencias: documentos, datos o fragmentos concretos.
Cómo se logra:
- Instrucciones explícitas
- Límites de alcance
- Sistemas automáticos como RAG
RAG
Retrieval-Augmented Generation — Combina un modelo generativo con recuperación de información interna. Usa embeddings para encontrar fragmentos relevantes.
Cuándo es ideal:
- Políticas, procedimientos, contratos
- FAQs internas y documentación
- Catálogos que cambian frecuentemente
De "modelo" a "sistema": herramientas, integraciones, agentes
El valor real viene al pasar de "chat" a "sistema"
Cuando la IA no solo responde, sino que integra, automatiza y ejecuta.
Integraciones
Conecta con correo, documentos, CRM, ERP, tickets y herramientas clave de tu empresa.
Estandarización
Entradas (formularios, plantillas) y salidas (tablas, campos obligatorios) estructuradas.
Human-in-the-loop
Aprobaciones, revisiones y responsables. La IA no actúa en solitario.
Observabilidad
Qué se pidió, qué salió, quién aprobó, métricas de rendimiento e impacto.
Los "agentes" aparecen cuando el sistema
- No solo genera texto, sino que decide pasos
- Ejecuta acciones en herramientas (CRM, email, etc.)
- Vuelve con un resultado final
⚠ Requiere controles: un agente puede amplificar errores si actúa sin supervisión.
Implicación práctica para directivos
Cómo "pensar" la IA correctamente en empresa
Es excelente en
- Transformar información (texto/documento) → output estructurado
- Actuar como "copiloto" para tareas repetitivas de conocimiento
Pero NO es
- Una fuente de verdad garantizada por defecto
- Infalible sin contexto y validación
Su fiabilidad depende de
- El contexto que le das
- El formato que exiges
- El control que aplicas
- Si la anclas a fuentes internas
Bottom line
Gestiona la IA como una herramienta de amplificación, no como una verdad. Con buen contexto, controles y validación, es increíblemente valiosa para tu empresa.
Tipos de modelos
Modelos predictivos "clásicos" (ML Tradicional)
¿Qué son?
Modelos para predecir un valor (número) o clasificar (categoría) a partir de variables estructuradas
Qué resuelven bien
Predicción de demanda
Forecasting de ventas, rotación de inventario
Scoring de riesgo
Probabilidad de impago, churn, conversión
Detección de anomalías
Fraude, comportamientos atípicos
Segmentación
Clustering de clientes o productos
Requisitos
Datos estructurados
Tablas con filas y columnas limpias
Variable objetivo definida
Qué quieres predecir o clasificar
Históricos suficientes
Mínimo cientos/miles de casos
Algoritmos principales: Regresión · Árboles de decisión · Random Forest · XGBoost · SVM · K-NN
Deep Learning para percepción: Visión y Audio
Redes de aprendizaje profundo para imagen, vídeo y sonido
Visión (Computer Vision)
Redes para imágenes/vídeo con casos en control de calidad, conteo de inventario, seguridad (EPI, zonas prohibidas), OCR y análisis de documentos escaneados.
Audio
Modelos para speech-to-text, identificación de hablantes, clasificación de llamadas, text-to-speech. Útiles en transcripción de reuniones, QA en call centers, formación.
Modelos de lenguaje (LLMs): el "motor" de la IA generativa
¿Qué son?
Redes neuronales masivas entrenadas con billones de palabras para predecir texto siguiente. Transformers decoder-only optimizados para generación y conversación.
Capacidades principales
Generación de texto
Redacción, reescritura, síntesis, resúmenes, transformación de formatos
Programación
Generación y análisis de código, debugging, documentación técnica
Razonamiento
Análisis complejo, cadenas de pensamiento (CoT), resolución de problemas
Estructuración
Extracción de datos, conversión a JSON/XML, clasificación y etiquetado
Generalistas
GPT-4, Claude, Gemini: Múltiples tareas y dominios
Especializados
Codex, Med-PaLM: Optimizados para dominios específicos
SLMs (Pequeños)
Phi, Mistral 7B: Ejecución local y on-premise
Arquitectura Transformer: Atención multi-cabeza + Feed-forward + Tokenización subword (BPE/WordPiece)
Embeddings: el "cerebro de búsqueda semántica"
Representación vectorial de significado
Modelos que convierten texto (o imágenes) en vectores de alta dimensión donde "significados similares" quedan cerca. No generan texto: representan.
Para qué sirven
Búsqueda semántica, clustering de tickets, deduplicación de documentos, recomendaciones.
Base de RAG
Son el fundamento de RAG. Permiten que un LLM responda basándose en documentos internos sin reentrenamiento.
Clave empresarial
Es el componente más "industrial" y estable. En muchos casos, embeddings + búsqueda es el primer paso efectivo.
Modelos de generación de contenido
No son LLMs de texto, pero completan la "fábrica de contenido" de tu empresa:
Generación de Imagen
Creatividades, prototipos, marketing, fichas, visuales de formación
Generación de Vídeo
Comunicación interna, formación, anuncios simples, material corporativo
Generación de Voz (TTS)
Onboarding, microlearning, IVR, avisos operativos
Clave empresarial
Si se usa para contenido externo, considerar marca, compliance, y evitar usos engañosos (deepfakes).
Agentes: cuando el sistema decide pasos y usa herramientas
Sistema inteligente autónomo
Una "capa" encima del modelo que planifica, decide acciones, llama herramientas y ejecuta partes del flujo.
Casos reales
Triar incidencias y crear tickets
Preparar borradores y proponer acciones
Generar reportes semanales
Automatizar tareas administrativas
Riesgos a considerar
Puede "hacer demasiado" sin permisos
Requiere gobernanza: límites, logs, validación
Amplificación de errores sin supervisión
Clave: Los agentes multiplican capacidades, pero necesitan diseño de permisos, logs y human-in-the-loop para decisiones críticas
Ecosistema IA
El stack real de IA en empresa
Una solución de IA rara vez es "un modelo" — Es un sistema con capas
Interfaz / Experiencia
Chat, panel, extensión, plugin, bot en Teams/Slack
Orquestación
Flujos, automatizaciones, agentes, validaciones
Conocimiento y Datos
Documentos internos, bases de datos, ERP/CRM, emails
Modelos
LLM, embeddings, visión, audio, predictivos
Gobierno
Permisos, auditoría, políticas, retención, seguridad
Lo importante
Lo que compras es principalmente integración + controles + operación, no solo capacidad del modelo.
Nueve niveles de herramientas de IA
Desde productividad individual hasta sistemas empresariales:
Prompting profesional
Qué es un prompt en términos prácticos
Un prompt NO es una pregunta casual
Es un brief operativo estructurado que contiene:
Prompt pobre
"Hazme un análisis de estos datos"
- Sin contexto ni objetivo
- Respuesta genérica
- Requiere múltiples iteraciones
Prompt profesional
"Actúa como analista financiero. Analiza estos datos de ventas Q4 2025 y genera un informe ejecutivo con: tendencias, anomalías, forecast Q1. Formato: tabla + bullets."
- Define rol, contexto y objetivo
- Especifica formato de salida
- Resultado útil al primer intento
Plantilla base universal (y por qué funciona)
Estructura estándar que maximiza calidad y consistencia:
¿Por qué funciona? Reduce improvisación y convierte el modelo en ejecutor con condiciones claras
Los 6 errores más comunes (y su corrección)
Evita estas trampas que degradan la calidad del output:
Objetivo ambiguo
"Analiza esto"
Especificar qué decisión necesitas tomar
Sin contexto
Pregunta sin información de fondo
Aportar datos mínimos necesarios
Formato abierto
"Dame ideas" (sin estructura)
Exigir formato: tabla, checklist, bullets
Exactitud sin fuentes
"Dame cifras del sector"
Aportar documentos o usar RAG/búsqueda
Demasiadas tareas
Todo en un único prompt complejo
Dividir en pasos secuenciales (chaining)
No controlar invención
Libertad total para inventar datos
Añadir reglas: "no inventes", "di si no sabes"
Prompting como diseño de procesos: "Prompt Chaining"
En trabajo real, un resultado final suele requerir etapas encadenadas
Cada paso genera un output estructurado que alimenta al siguiente
Extracción/Estructuración
Convertir input en tabla o esquema
Ejemplo: Convertir email en tabla de tareas
Análisis
Identificar riesgos, inconsistencias, oportunidades
Ejemplo: Detectar dependencias críticas
Propuesta
Recomendaciones, plan, borradores
Ejemplo: Plan de acción priorizado
Verificación y Checklist
Revisar supuestos, datos faltantes, "red flags"
Ejemplo: Checklist de validación
Beneficio: Reduce alucinaciones porque cada paso se apoya en output estructurado del paso anterior, creando una cadena de validación continua.
Pautas para "no inventes": cómo pedir incertidumbre
Los LLMs tienden a completar huecos — Pide explícitamente control para hacer visible el riesgo
Supuestos
Listar supuestos que ha hecho para concluir algo
"Lista 3 supuestos clave en tu respuesta"
Desconocidos críticos
Qué información falta para decidir con seguridad
"¿Qué datos faltan para validar esto?"
Preguntas
5–10 preguntas para completar el análisis
"Genera 7 preguntas para profundizar"
Confianza
Indicador (alta/media/baja) y por qué
"Indica nivel de confianza y justifica"
Resultado: No elimina errores, pero hace visible el riesgo y evita decisiones basadas en suposiciones sin evidencia.
Prompts como "activos empresariales"
Si quieres que la IA se use de forma consistente — Trata los prompts como un activo
Componentes de una "Biblioteca de Prompts"
Organización
Por área: ventas, compras, finanzas, RRHH, ops
Versión
Quién lo mantiene, fecha, cambios
Ejemplos y test cases
Inputs típicos para validar
Reglas de uso
Qué datos se permiten, cómo validar
Plantillas aprobadas
Formatos estándar para reportes, propuestas, SOPs
Sin estructura
"Habilidad individual"
Cada uno hace su prompt
Con biblioteca
"Capacidad organizativa"
Estandarizada, documentada, validada
¿Por qué Q1 2026 es el momento?
La IA ya no es "I+D": hoy es una palanca práctica para productividad, calidad y velocidad
Barreras de entrada mucho más bajas que hace dos años.
Tecnología
Modelos potentes, multimodalidad, asistentes listos
Integración
IA dentro de suites y apps (menos fricción)
Coste accesible
Pilotos de bajo coste, amplía según ROI
Datos disponibles
Emails, PDFs, Excel, ERP/CRM, tickets
Metodologías claras
Prompts, RAG, agentes, pilotos 2–4 semanas
Ventaja competitiva
Quien se mueve primero gana en velocidad
El momento es AHORA
Tecnología lista · Costes accesibles · ROI medible · Barreras mínimas